
Kafka Connect is an integral part of Apache Kafka and integrates other systems with Kafka. For example, Kafka Connect can be used to transfer changes from a database (source) to Kafka and write them from there to another data storage system (sink), thus allowing other applications/services (e.g. dashboard) to access real-time data.
Kafka Connect provides a runtime and framework for creating and running robust data pipelines, of which Kafka is an indispensable part. Kafka Connect has been tested in many challenging conditions so far and has proven to be robust at scale. Kafka Connect allows you to define data pipelines in a JSON file and launch data pipelines without writing any code.
In Kafka Connect, pipelines are divided into two:
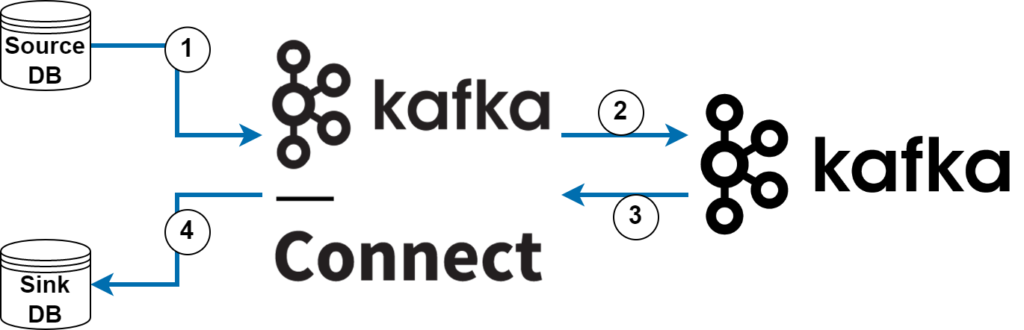
Source pipelines: Bringing data from external systems to Kafka (Figure-1, 1 and 2)
Sink pipelines: Transporting data from Kafka to external systems (Figure-1, 3 and 4)
For these two different pipelines, one side must be Kafka; End for source, start for sink.
Kafka Connect Features
Let’s take a closer look at the features that make Kafka Connect a very popular platform for creating data pipelines and integrating systems.
1. Pluggable Architecture
Kafka Connect provides underlying logic and a common API to flexibly ingest and extract data from external systems into Kafka. Thus, it can work with many plugins on this basic logic and API. The Kafka community has created hundreds of plugins to interact with databases, storage systems, and various common protocols. This makes starting even complex jobs quick and easy. You can even write your own plugin if none of the existing plugins meet your needs. Kafka Connect allows you to create complex pipelines by combining these plugins. Plugins used to define the pipeline are called Connector plug-ins. There are different types of connector plug-ins:
• Source connectors: Moving data from external systems to Kafka
• Sink connectors: Moving data from Kafka to external systems
• Converters: Converting data between Kafka and external systems
• Transformations: Transforming data flowing through Kafka Connect
• Predicates: Apply the conversion operation based on a condition
A pipeline consists of a single connector and converter, and optional transformations and predicates can be added. A simple ETL pipeline is shown in Figure-2 below. One source connector, one transformation (a record filter) and converter.

Besides Connector plug-ins, there is another set of plug-ins used to customize Kafka Connect itself. These are called worker plug-ins:
• REST Extensions: To customize the REST API.
• Configuration Providers: To set configurations dynamically at runtime.
• Connector Client Config Override Policies: Allows users to change some of the Kafka client configurations used by the connector.
2. Scalability and Reliability
Kafka Connect runs as a separate cluster on different servers other than the Kafka cluster. Thus, it can scale independently of Kafka. Each server in the Connect cluster is called a worker. You can add or remove new workers while Connect is running. In this way, you can dynamically balance resources according to load. Workers in the cluster cooperate and each undertakes some of the workload. This makes Kafka Connect very reliable and resilient because if one worker crashes, others can take over its workload.
3. Declarative Pipeline Definition
Kafka Connect allows you to define the pipeline declaratively. This happens without writing any code using connector plugins. Pipelines are defined by JSON files that describe the plugins to be used and their configurations. This enables data engineers to design complex pipelines without writing thousands of lines of code. Then, these defined JSON files are sent to Connect via REST API and the pipeline is started. Of course, with the API, not only starting but also operations such as stopping, pausing, status review and configuration change are performed.
4. Connect is Part of Apache Kafka
You do not have to download a separate binary to install and use Connect. Connect comes ready in the Kafka binary. You can start Kafka and Connect with the same files. However, Connect definitely needs Kafka to work. Connect is one of the complementary and important components of the Kafka ecosystem. Another advantage of being developed together with Kafka is that Kafka has a very dynamic and strong community, and this advantage has enabled Connect to become very good in a short time. Developers and admins who know Kafka will be unfamiliar with Connect. For those who know Kafka, there is a positive transfer in switching to Connect, it makes learning easier. Additionally, Connect uses Kafka like a database, so it does not need additional storage (e.g. RDBMS, Postgresql) to store state information other than Kafka.
5. Connect Use Cases
Kafka Connect can be used for a wide variety of situations involving ingesting data into or out of Kafka.
5.1. Capturing database changes (Change Data Capture – CDC)
There is a general need to capture changes in operational databases and instantly transfer them to another location. This capture event is called Change Data Capture (CDC). You can make CDC in two ways. First; by constantly querying it, which puts additional load on the database. Latter; By reading change logs. This method is more reliable and does not have any additional burden on the database. Some plugins, such as Debezium, allow using the second method.
• 5.2. Mirroring Kafka clusters
Kafka clusters are mirrored for reasons such as establishing disaster recovery environments, migrating clusters, or replicating to a different geographical region (geo-replication). It may be desirable to separate the write-intensive cluster from the read-intensive cluster.
• 5.3. Be a part of building a data lake
You can use Kafka Connect to copy data to a data lake or archive it to affordable storage such as Amazon S3. Connect has no data storage feature, while Kafka has limited and short-term data storage, so if you need to write large amounts of data somewhere or store it for a long time (for example, for auditing purposes), you can write data to S3 with Connect. If the data is needed again in the future, you can transfer the data back at any time with Kafka Connect.
• 5.4. Log Aggregations
It is often useful to store and collect data such as logs, metrics, and events from all your applications. When data is in one place it is much easier to analyze. Additionally, with the rise of the cloud, containers, and Kubernetes, you should expect the infrastructure to completely remove your workloads and rebuild them from scratch if it detects an error. This means that it is important to store data such as logs in a central location rather than in local repositories of dispersed applications to prevent loss. Kafka is an excellent choice for data aggregation because it can process large volumes of data with very low latency.
• 5.5. Modernization of classical systems
Modern architectures have moved towards the deployment of many small applications rather than a single monolith. This can cause problems with existing systems that are not designed to handle the workload of communicating with multiple applications. They also often cannot support real-time data processing. Since Kafka is a pub/sub messaging system, it creates a separation between applications sending data to it and those reading data from it. This makes it a handy tool to use as a buffer between different systems
References
- Featured Image: Photo by Alexas_Fotos on Unsplash
- Kafka Connect, Mickael Maison, Kate Stanley, O’Reilly, 2023.